Automatic GUI Creation
Generating Java source code from formal descriptions
4. Code Generation
This section explains how Java code for the plug-in is generated. The first part discusses general quality requirements on plug-in source code and how well these have been met in the prototype. The second part explains the design of the prototype code generator.
4.1 Generating source code of high quality
Generating source code is not trivial, as there are many dependencies between various files and code parts. The fact that the profession of programmers still exists (and is rather well paid) also indicates that automatically generated source code cannot solve all problems. In the case of generating plug-ins there are several such issues—user interface layout and logic, data interdependencies and program logic are all extremely hard to handle well in an automated fashion. The introduction of automated tools will not remove the need for plug-in developers, as several parts of the code must be inserted by hand.
In order to insert the missing parts, the generated Java source code must be possible to read, understand, and change by a plug-in programmer. Requiring that the programmer shall be able to read and understand the code is actually a rather hard requirement, as it means that the output code must be generally well-written and commented. The code must be of a high quality and should follow the same code conventions that the programmer is used to. In specifics this means that the generated code must be (in parts from Huss, 1993):
- General
- Modularized
- Indented
- Commented
- Correct
- Extensible
- Robust
- Compatible
- Efficient
The source code requirements
That the code be general means that it should be possible to use for as many purposes as possible. Not only do there exist several distinct types of plug-ins, but it may also be the case that other plug-in platforms may be used. The generated code must thus be as general as possible, making it possible to reuse for other purposes.
Modularization means dividing the generated code into methods and classes responsible for parts of the functionality. Together with the indentation and commenting this highly improves the readability of the code for the plug-in programmer.
Correctness means that the generated code must be possible to compile or that it at least is in such a state that it can be compiled with minimal additions. There should be no syntactic errors present in the code, and the semantics should of course also make sense, even if it the generated code is only a partial solution.
Extensibility means that the generated code shall be simple to extend with new functionality, either by changing or adding new methods. This requirement is only partially met by generating well-structured code, the other part needed is preserving these additions when generating the plug-in again.
Robustness means handling invalid user input in correct ways. The generated components must check their entry to the largest possible extent for errors, and should fail gracefully.
Compatibility means supporting the plug-in platform, something that in parts collide with the demand of keeping the generated code as general as possible. A special compatibility demand has been that the components should be possible to layout with the visual tools in Borland JBuilder 3. This means keeping the interface creation parts of the code within methods with particular names.
Finally the requirement of efficiency means that the generated code should not be any slower to execute than hand-made code. No additional lookups or run-time conversions can be tolerated in the output code—all such computations should be made already when generating the code. Limits in the design In an ideal world, the generated plug-in programs should always fulfill all of these requirements. However, in the real world some of these requirements cause conflicts or excessive work when generating the plug-ins. In the following the design decisions that have put a limit to these requirements are explained in more detail.
The generated plug-ins are not totally correct, as they lack several important features. Some of these features have been left out as they were outside the original scope of this thesis, i.e. not related to the GUI generation. Others have been left out as they proved impossible to handle by automated means, as the component layout. Many parts left out in this way have been commented in the output source code.
The code is not always possible to compile directly as a result of using some method names that are not declared in the code. The idea is to allow the programmer to choose either an adequate superclass or to implement the method manually. In order to make this choice more obvious, no default alternative is generated.
The generated code is not fully extensible, as it is hard to avoid overwriting the source code on disk. That kind of support requires parsing it and keeping track of user changes, something that would have been a far to large task to undertake.
As there was a conflict between making the code more general or fully compatible with the plug-in platform used today, the choice was made to not make the code dependent on the plug-in platform. This means that the generated classes does not inherit any specialized superclasses from the plug-in framework.
4.2 Layered code generation
There are basically two implementation strategies for automatic code generation. The output source code can either be partially written in separate files, called templates, or created totally by the program. Using templates usually makes it easier to maintain the code generator, as many changes can be made directly to the template files instead of in the generator.
Using templates when generating source code of high quality may cause problems, however, as it is important that the output be given a consistent formatting. It is also difficult to maintain the tight connection between the code generator and the templates, as these are split up into several files. The better solution is therefore to handle the code generation inside several specialized modules in the program.
An approach to generate the source code totally from within the program calls for some modularization, as it would otherwise be almost impossible to guarantee high quality of the output source code. The code generation in the prototype application has therefore been split into three layers—the Java syntax layer, the file or class layer, and the overall plug-in layer (see figure 5).
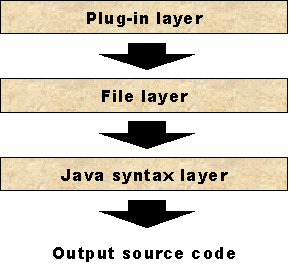
Figure 5. The source code generation is divided into three layers, each one only calling functions in the layer below. The syntax layer handles the syntactic constructs in Java, the file layer handles the dependencies between different files, and the plug-in layer controls what to generate.
The Java syntax layer
The Java syntax layer generates the actual text files containing the source code. It creates code for many of the basic syntactic constructs in the Java programming language—for example class, variable, and method declarations. The output text is also formatted following the recommendations in the Java coding style guide (Reddy, 1998).
The use of a separate syntax layer guarantees that all the generated code will follow the same well-defined code conventions, while at the same time making it easier to change style. As an example, the number of spaces for each indentation level can be changed by modifying only a single constant in the prototype. The interfaces provided also makes it easier to generate the source code, as much complexity and details can be hidden.
The syntax layer consists of a set of classes, each representing a syntactic construct in the language. From these classes the actual instances can be created and combined in the same ways that the Java syntax allows, making it impossible to generate output code that is not syntactically valid for those constructs (see figure 6). The top object in such a hierarchy is always a Java source file, and when writing those objects to disk all substructures are also written.
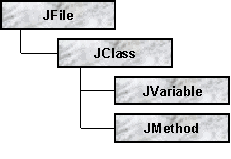
Figure 6. A simplified Java syntax structure. The file object can only have classes as children. The classes, in turn, can only accept variables and methods. These rules makes it harder to generate a non-valid Java file.
In order to keep the syntax layer more effective and compact, only top level declarations are handled as specialized objects. Declarations and the actual code inside methods are handled as simple strings, opening up for syntactic errors and misspellings. It would, however, be difficult to create all the code as a reversed parse tree, in particular as that would require creating lots of objects in other parts of the code.
The file layer
A plug-in may consist of a considerable amount of source code files, each containing one or more Java classes. In order to structure those files correctly, and keep track of changing variable and method names, a file layer is inserted on top of the syntax layer to handle this. The file layer also inserts code and comments that are the same for all plug-ins.
The file layer consists of a set of classes, each modeling a single output file. Unlike the syntax layer, the file objects may not be freely created and combined, and other layers can only explicitly create two files—the plug-in file and the tab file. These two automatically create all other files below them in the hierarchy, in order to assure that all dependencies become correct.
The file objects also allows some level of manipulation through methods that can add code to the various files. These calls are translated to the syntax layer, and each file object keeps an internal reference to the syntax layer objects needed. The file layer also communicates horizontally to a large extent, in order to assure that variable and method names are the same in the declaration and when using them.
By using a specialized file layer, the complicated dependencies between the files (as seen in figure 7) can be kept under control without much effort. The problems with exporting and importing variables and methods can also be approached in a safer manner, as each file object is responsible for creating the references to itself.
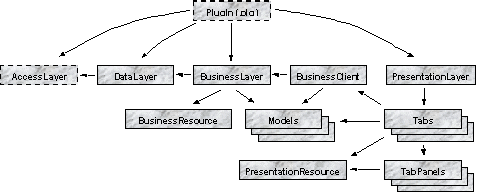
Figure 7. The structure of the plug-in source code files. Dependencies between files have been drawn as arrows from one class to another. Files with a dotted border are currently not generated by the prototype.
The plug-in layer
On top of the file layer the full plug-in generation is placed, handling such things as creating the tabs, the components, and everything that is related to the actual MIB fields. The major part of this layer consists of the component generation, as the prototype generates little more than skeleton code for the other parts.
The components and all related code are generated by component generator objects, making the component generation modularized and extensible. Apart from creating the actual source code, they also provide the simple demonstrations of the components that are available in the interface (seen in figure 4).
It is not trivial to add new components to the system, however, since each component is also responsible for generating its own source code. The number of component generators has therefore been limited in the prototype. Only the most commonly used components, such as text and number fields, have been implemented in the prototype (see table 2). Some extensions to the standard Java components have also been made in order to simplify the code generated.
The component generators can be freely interchanged, with the exception of the table component generator. They all implement a uniform interface and read the type information direct from the symbols, allowing each component generator to handle its own subset of the type semantics. Currently the prototype does not handle type conversions from the underlying data types to the types needed in the components, since that conversion is complicated to generate automatically and is outside the scope of this thesis.
In the current prototype implementation several of the plug-in layers are not completely generated. The access layer and the plug-in specification files are not generated at all (see figure 7), partly because they have a trivial structure and are simple to write by hand. The data and business layers are only generated as stub code, leaving out important parts of data conversion and inner mechanics. Fixing this would probably require a substantial effort, especially if the goal is to keep the generated plug-ins as general and multi-purpose as possible.
